How to Build a Revenue-Focused SaaS PPC Testing Programme
Learn to create a structured SaaS PPC testing programme that prioritises revenue impact across campaigns, audiences, and landing pages.

Most SaaS teams run PPC experiments. They test ad copy, landing page variants, bid strategies, and audience segments. The results come back, a winner is declared, and the optimisation log gets updated. Three months later, pipeline looks the same.
The problem is not a lack of testing. It is that the experiments are measuring the wrong things. A 20% lift in click-through rate and a 15% improvement in form submissions look credible until you trace those leads through to closed-won revenue and find no corresponding movement. The experiments produced data. They did not produce learning.
A revenue-focused SaaS PPC testing programme is built on a different premise: that every experiment must be connected, from design to decision, to a measurable hypothesis about pipeline or revenue. Not conversions in the platform. Pipeline and revenue that shows up in the CRM.
This article covers how to build that programme from the ground up.
Why Most SaaS PPC Testing Programmes Stall at the Platform Level
The default testing culture in PPC is borrowed from direct response: form a hypothesis, run the test, measure the conversion metric, call the winner. For SaaS, this creates a structural problem.
The conversion metric available in Google Ads or LinkedIn Campaign Manager is a form fill, a trial sign-up, or a click event. It is a proxy for revenue, not revenue itself. When you optimise for that proxy, you get very good at producing it, and nothing else is guaranteed to follow.
According to TripleDart’s 2026 SaaS PPC report, only 43% of B2B SaaS companies have successfully implemented full-funnel reporting. That means a majority of teams are making test decisions based on data that stops at the landing page. They are declaring winners without knowing whether the winning variant produced better pipeline, better deal quality, or better average deal size.
The second structural problem is test isolation. Campaign experiments, audience tests, landing page tests, and offer tests are often run independently, inside separate platforms, by different people. There is no mechanism for connecting what was learned in a campaign bid strategy test to what was happening on the landing page at the same time. The tests produce noise.
A revenue-focused testing programme does not avoid these platforms. It builds a layer above them: one that connects experiment outputs to CRM data, maintains test isolation where it matters, and refuses to call a winner until a revenue signal has been checked.
The Architecture of a Revenue-Focused PPC Testing Programme
Define What You Are Actually Testing For
Before any test is designed, the team needs agreement on what a winning result looks like at the revenue level. This is not the same as agreeing on a conversion metric.
For a SaaS business with a 60, 90 day sales cycle, the relevant downstream signals might be MQL-to-SQL conversion rate, cost-per-opportunity, pipeline value generated, or average deal size by segment. The specific metric depends on the GTM motion: a product-led growth model where trials convert to paid is a different measurement environment from a sales-led enterprise motion where demos flow into multi-stakeholder cycles.
The testing programme needs a primary revenue proxy for each experiment layer: one metric that sits close enough to revenue to be meaningful, but moves quickly enough to give signal within the test window. For many SaaS teams, SQL creation rate or cost-per-SQL is that metric. It is downstream of form fills but upstream of final pipeline, and it moves within weeks rather than quarters.
Without this pre-agreement, experiments get called based on whatever metric shows a visible change first. Usually, that is a click or a form fill.
Structure Your Experiment Backlog by Test Layer
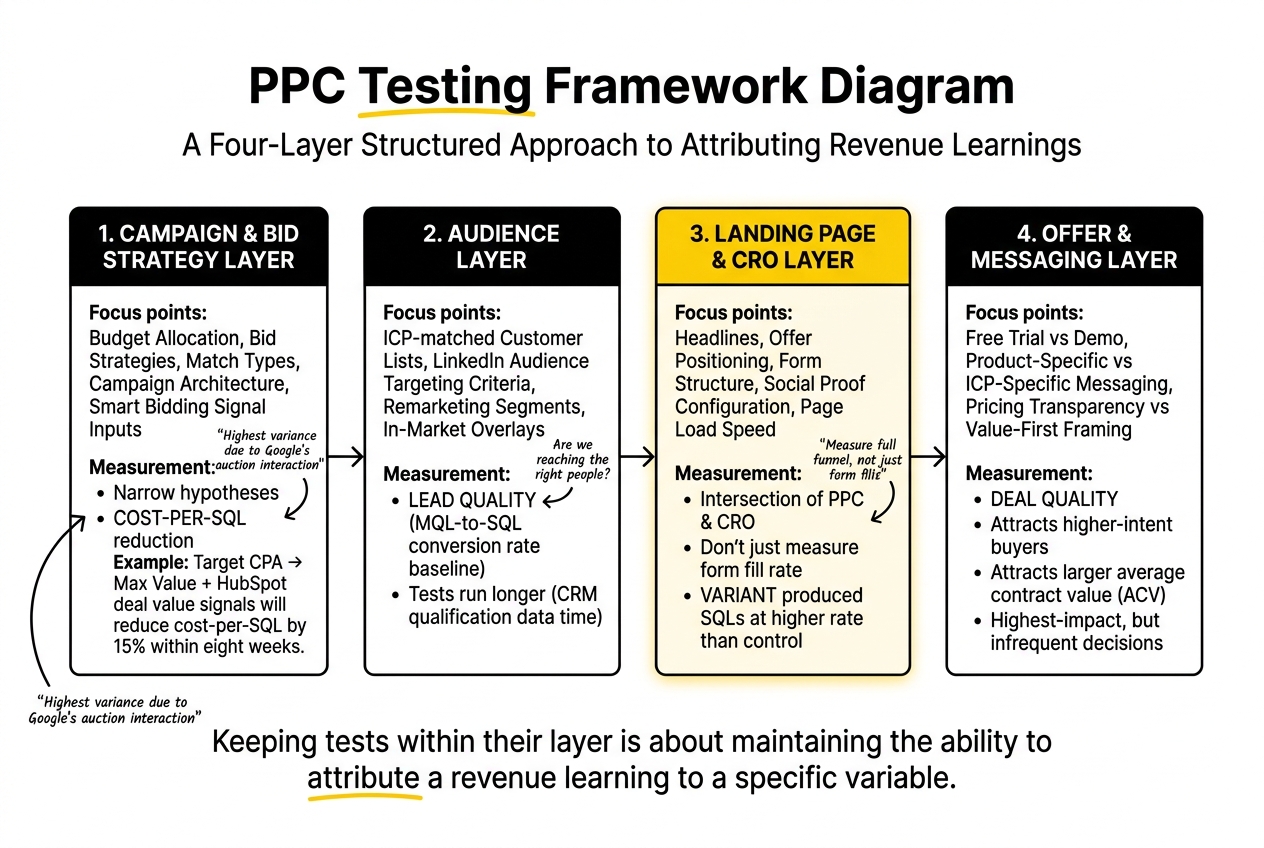
A useful way to structure a SaaS PPC testing programme is to separate tests into four distinct layers, each with its own hypothesis format, measurement approach, and learning outcome.
Campaign and bid strategy layer. Tests at this level examine how the platform allocates budget: bid strategies, match types, campaign architecture, and Smart Bidding signal inputs. These tests often have the highest variance because they are interacting with Google’s auction in ways that are hard to isolate. Hypotheses here should be narrow: “Switching from Target CPA to Maximise Conversion Value, with deal value signals imported from HubSpot, will reduce cost-per-SQL by 15% within eight weeks.”
Audience layer. Tests at this level examine who is being reached: ICP-matched customer lists, LinkedIn audience targeting criteria, remarketing segments, and in-market audience overlays. The relevant revenue question is usually lead quality: does this audience segment produce a higher MQL-to-SQL conversion rate than the baseline? Audience tests often run longer than campaign tests because qualification data takes time to appear in the CRM.
Landing page and CRO layer. Tests at this level examine what happens once the click lands. Headline variants, offer positioning, form structure, social proof configuration, and page load speed all belong here. This is where PPC testing and CRO genuinely intersect, and where treating them as separate programmes creates the most waste. A landing page test that only measures the form fill rate is half a test. The full test measures whether the variant produced SQLs at a higher rate than the control.
Offer and messaging layer. Tests at this level examine what is being promised: free trial versus demo, product-specific messaging versus ICP-specific messaging, pricing transparency versus value-first framing. These are often the highest-impact tests and the ones teams run least frequently, because they feel like bigger decisions than adjusting a bid strategy. The revenue hypothesis here is usually about deal quality: does a different offer attract a higher-intent buyer with a larger average contract value?
Keeping tests within their layer is not rigidity for its own sake. It is about maintaining the ability to attribute a revenue learning to a specific variable. If you change the bid strategy, the audience, and the landing page simultaneously, and pipeline improves, you have learned very little.
Set Up Revenue Signal Routing Before You Run a Single Test
The most common reason SaaS PPC testing programmes stay at the platform level is not a lack of ambition. It is that the revenue data is not connected to the experiment in time to be useful.
The infrastructure needed is not complicated, but it needs to be in place before testing starts. At minimum, the programme needs three things: UTM parameters on every ad that persist through to the CRM record; a way to tag leads with the experiment variant they came through (this can be done through hidden form fields passed via UTM or through a URL parameter that triggers CRM field population); and a reporting view in the CRM that filters pipeline and revenue by those tags.
With this in place, when a campaign test runs, the team can see not only how many leads each variant produced but what those leads became: SQLs, opportunities, closed deals. The test result is no longer a platform metric. It is a revenue signal.
The setup typically takes a few days of collaboration between the PPC team and whoever owns CRM configuration. It is often not done because no one owns the brief. Making someone responsible for it is a strategic decision, not a technical one.
Statistical Significance in SaaS PPC Testing
Why Standard Thresholds Are Harder to Hit in B2B SaaS
The 95% confidence threshold that gets cited in most CRO and experimentation guidance is harder to achieve in B2B SaaS PPC than in e-commerce or B2C contexts. The reasons are structural.
SaaS PPC typically runs on lower conversion volumes than the contexts those thresholds were designed for. According to Peep Laja’s work at CXL, 250 to 400 conversions per variation is the typical requirement to reach statistical significance at 95% confidence. A B2B SaaS campaign generating 40 to 80 form fills per month is not going to hit that threshold in a reasonable test window. Waiting until it does means either running tests for six months or declaring winners on insufficient data.
There are two practical responses to this. The first is to move the measurement point closer to volume: instead of measuring SQL creation (which happens at a rate of, say, 25 per month), measure qualified form submissions or lead quality score, which happen more frequently and can proxy the same intent signal. The second is to accept lower confidence levels for directional tests while reserving 95% confidence requirements for decisions that will result in large budget shifts or structural account changes.
The key discipline is knowing which type of test you are running before you run it. A directional test to decide whether a hypothesis is worth a larger investment is different from a confirmatory test that will determine account structure. Mixing them produces the false confidence that creates bad scaling decisions.
Test Duration and Business Cycle Alignment
SaaS buying has seasonality and business cycle patterns that can distort PPC test results if a test window is too short. Budget approvals cluster at the start of quarters. Procurement activity slows in August and December. A two-week test that spans a period of unusual buying activity will not reflect normal performance.
The minimum test window for a SaaS PPC experiment with any revenue signal component is four to six weeks, covering at least one full business cycle. For audience tests and offer tests, which require CRM data to appear, eight weeks is often more realistic.
Resisting the pressure to call tests early is one of the most important habits a PPC testing programme can develop. A result that shows a 35% improvement after one week will regress. The pipeline data that follows rarely confirms the early click signal.
Cross-Funnel PPC Experiments for Revenue Growth
Cross-funnel experiments connect what happens at the top of the paid media funnel to what eventually emerges at the bottom of the revenue funnel. They are harder to design and slower to read, but they produce the most durable learning.
A cross-funnel experiment typically works as follows: two or more audience segments or ad variants are run simultaneously, with both CRM tagging and MQL-to-SQL tracking in place. The experiment does not just ask “which variant produces more leads?” It asks “which variant produces leads that become pipeline at a higher rate, and at what cost-per-opportunity?”
The Refine Labs research on demand creation versus demand capture is relevant here. The argument is that optimising purely for in-market, high-intent clicks tends to attract buyers who were already going to find you, while demand creation activity attracts buyers earlier in the cycle who close at higher ACV. Cross-funnel PPC experiments can test whether different keyword intent levels, audience segments, or offer types attract different buyer profiles, and which profiles create more revenue value over a 90 to 180 day window.
For Series B SaaS teams running dual GTM motions (product-led and sales-led), cross-funnel experiments can identify which paid channels and messages reliably attract the high-ACV buyers sales needs to hit quota, as opposed to the self-serve trials that PLG conversion tracks separately.
Integrating PPC Testing with CRO
The most efficient version of a SaaS PPC testing programme runs PPC and CRO as one coordinated experiment system, not two parallel programmes.
When PPC and CRO are separate, a common failure mode occurs: PPC optimises ad messaging to attract a specific type of click, and then sends that click to a landing page designed around a different message. The conversion rate suffers, the PPC team blames the landing page, and the CRO team blames the targeting. No one learns anything about what the ideal visitor actually needed to see.
A coordinated approach links paid search tests directly to landing page variants. If the PPC team tests two ad message angles, “reduce churn” versus “consolidate your stack,” each ad variant lands on a page that continues the same message. The experiment measures not just which ad angle gets more clicks, but which message-to-page combination produces the highest cost-per-SQL.
This requires shared ownership of experiment design, which is an organisational question as much as a technical one. But it is worth solving. PPC and CRO operating as separate testing programmes is a significant source of wasted learning in SaaS growth teams.
Metrics That Actually Belong in a SaaS PPC Testing Programme
The following is a practical distinction between metrics that should appear in your test results and metrics that should stay in the platform view only.
In your test decision framework:
- Cost-per-SQL (the primary revenue proxy for most sales-led SaaS)
- MQL-to-SQL conversion rate by variant
- Pipeline value generated per £ of ad spend
- Average deal size by audience segment or offer variant
- Opportunity-to-close rate where the sales cycle is short enough to observe within the test window
In your platform optimisation view, but not in test decisions:
- Click-through rate
- Cost-per-click
- Form conversion rate
- Quality Score
- Impression share
CTR and conversion rate are useful for diagnosing what is happening in the auction and on the landing page. They are not useful for deciding whether an experiment produced revenue learning. Teams that conflate the two end up optimising for form fills and wondering why pipeline does not follow.

Reporting That Supports Revenue Learning
A PPC testing programme is only as good as the reporting structure that surrounds it. If test results are communicated as “variant B won with a 22% higher conversion rate,” the revenue learning has been lost before it reaches a decision-maker.
Experiment reports for a revenue-focused programme should answer three questions: what was the hypothesis, what did the revenue signal show, and what is the recommended next action based on that signal?
The “next action” framing matters. A test that produced inconclusive revenue data is not a failed test. It is evidence that the hypothesis was too vague, the test window was too short, or the measurement was not yet in place. The right next action might be to refine the setup and rerun, not to move on.
Transparent reporting of PPC test results builds the kind of institutional knowledge that compounds over time. A testing log that captures not just what won but why the team believed it would win, and what the revenue data actually showed, creates a learning asset that improves the programme with every iteration.
Avoiding Common Pitfalls in SaaS PPC Testing
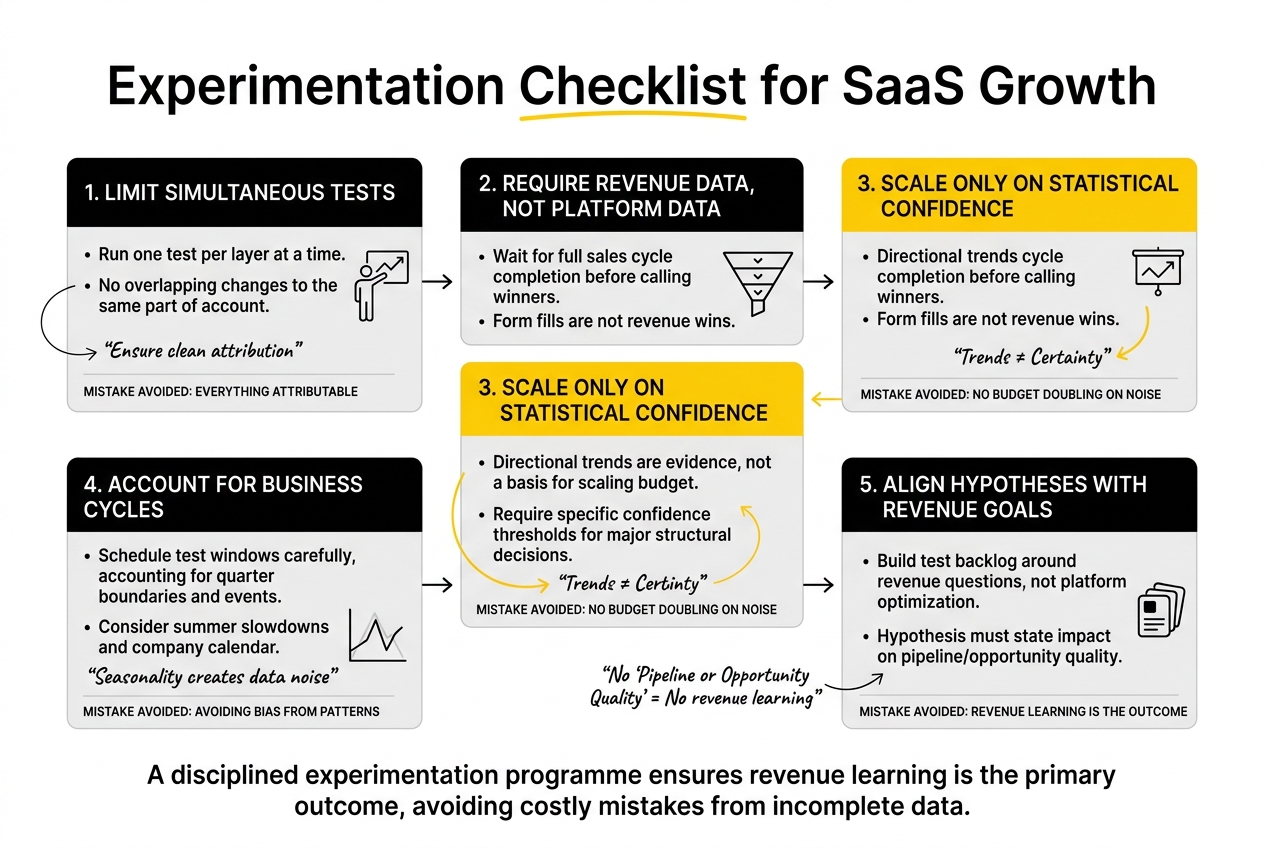
Running too many tests simultaneously. The natural instinct is to test everything at once. The result is that nothing is attributable to anything. A disciplined programme runs one test per layer at a time, with no overlapping changes to the same part of the account.
Calling winners on platform data before revenue data arrives. A landing page variant that produces 30% more form fills is not a winner until you know what those form fills became. In a 60-day sales cycle, the final test result is not available for 60 days after the test closes.
Scaling budgets on directional tests. A directional test showing a positive trend is evidence worth pursuing. It is not a basis for doubling spend. Scale budget only on tests that have reached the appropriate confidence threshold for a major structural decision.
Ignoring seasonality. A test that runs across a quarter boundary, a summer slowdown, or a company event will pick up that noise in the data. Account for business cycle patterns when scheduling the test window.
Misaligning test hypotheses with revenue goals. The most common root cause of all these problems is a test backlog that was built around platform optimisation questions rather than revenue questions. If the hypothesis does not contain a statement about what will happen to pipeline or opportunity quality, it is not a revenue learning experiment.
Building the Testing Velocity That Creates Compounding Learning
The goal of a SaaS PPC testing programme is not to run more tests. It is to run tests that produce reusable knowledge about what drives revenue from paid channels.
A team running four to six well-designed revenue experiments per quarter, each with CRM integration and a clear hypothesis about pipeline or opportunity quality, will compound their paid media effectiveness faster than a team running 20 platform-level tests with no downstream measurement.
This is because the learning from a revenue test transfers. If you learn that a specific ICP audience segment on LinkedIn produces a 45% higher MQL-to-SQL rate than your broad targeting, that knowledge shapes not just your next LinkedIn test but your Google Ads audience strategy, your landing page messaging priorities, and potentially your CRM lead scoring logic. Revenue learning is cross-functional by nature.
For Heads of Growth thinking about how to build this programme from scratch, the right starting point is not the experiment backlog. It is the measurement infrastructure. Get the UTM-to-CRM tagging in place. Agree on the primary revenue proxy for your GTM motion. Build the CRM report that shows pipeline by experiment variant. Then start testing.
The experiments are only as good as the infrastructure beneath them.
If you need support connecting your PPC setup to pipeline measurement, or structuring an experiment programme around your GTM motion, this is the kind of work we do regularly with SaaS PPC teams. Worth a conversation if you are at that point.
Frequently Asked Questions
What are the key components of a successful PPC testing programme for SaaS?
A successful SaaS PPC testing programme needs four things: a clear revenue proxy metric that each test is measured against (not just a platform conversion event), CRM integration that connects ad variants to pipeline and opportunity data, a structured test backlog separated by layer (campaign, audience, landing page, offer), and a reporting framework that captures the revenue signal rather than just the click or form fill outcome. Infrastructure comes before experimentation.
How can SaaS companies measure the revenue impact of their PPC tests?
Tag every ad variant with UTM parameters that persist through to the CRM record. Use hidden form fields or URL parameter logic to stamp the CRM lead record with the experiment variant it came from. Build a CRM report that shows pipeline value, SQL count, and opportunity-to-close rate filtered by variant tag. This allows you to compare not just how many leads each variant produced but what those leads became in terms of qualified pipeline and revenue.
What methodologies can be used to run effective PPC experiments in the SaaS sector?
Separate tests into distinct layers: campaign and bid strategy, audience, landing page, and offer. Run one test per layer at a time. Set the hypothesis before the test starts and state what revenue movement would constitute a win. Use a minimum four-to-six-week test window to account for SaaS buying cycles. Accept directional confidence levels for exploratory tests and reserve 95% statistical significance thresholds for tests that will result in major structural or budget decisions.
How do audience targeting strategies influence PPC performance in SaaS?
Audience targeting determines the quality and intent level of the leads entering the funnel, which directly shapes downstream MQL-to-SQL conversion rates and average deal size. Testing audience segments against CRM outcome data, not just lead volume, reveals which segments produce the highest cost-per-SQL and highest-value opportunities. For SaaS teams running both PLG and sales-led motions, audience tests can identify which paid segments reliably attract the high-ACV buyers the sales team needs, distinct from the self-serve trial volume the PLG motion tracks separately.
What role do landing pages play in the success of PPC campaigns for SaaS businesses?
Landing pages are the point where paid traffic intent either converts to a qualified lead or exits. They should be tested in direct coordination with the paid ad messaging, not as a separate CRO programme. When the message in the ad matches the message on the landing page, conversion rates improve and lead quality tends to be higher because the visitor self-selected based on a specific value claim. Testing ad message and landing page as a combined unit, measuring the outcome at the SQL level, produces more durable learning than testing either element independently.
How can SaaS companies integrate PPC testing with conversion rate optimisation?
Run PPC and CRO as one experiment system with shared ownership of the hypothesis, the test design, and the measurement outcome. Ensure that each ad variant lands on a matching landing page variant, so the experiment measures a message-to-page combination rather than an isolated element. Measure test outcomes at the SQL or opportunity level, not the form fill level. This requires a brief coordination process between the paid media team and whoever owns landing page testing, but the compound effect on pipeline efficiency is significant.
What metrics should SaaS growth leaders focus on to evaluate PPC success?
Cost-per-SQL and MQL-to-SQL conversion rate by variant are the primary metrics for test evaluation. Pipeline value generated per unit of ad spend is the broader programme health metric. Average deal size by audience segment or offer variant tells you whether your targeting is attracting the right buyer profile. Click-through rate, cost-per-click, and form conversion rate are useful for diagnosing platform and landing page mechanics, but they should not be the basis for declaring a test winner or making scaling decisions.
How can statistical significance be achieved in PPC testing for SaaS?
The standard 95% confidence threshold requires roughly 250 to 400 conversions per variant, which is difficult to reach in a typical B2B SaaS PPC account. The practical approach is to distinguish between directional tests, where 80% confidence is enough to inform the next iteration, and confirmatory tests, where 95% confidence is required before making structural budget decisions. For lower-volume accounts, move the measurement point to the metric that happens most frequently (such as MQL creation rather than SQL), and run tests for a minimum of four to six weeks to cover at least one full business cycle.
What are common pitfalls to avoid when implementing a PPC testing programme in SaaS?
The most common pitfalls are: calling winners on platform data before CRM revenue data has had time to arrive; running overlapping tests across multiple layers simultaneously, which destroys attribution; scaling budget on directional tests before they have reached the appropriate confidence level; and building the experiment backlog around platform optimisation questions rather than revenue hypotheses. The root cause of all of these is the same: the test framework was designed to answer platform questions, not revenue questions.
How can SaaS companies ensure transparent reporting of PPC test results?
Build experiment reports around three questions: what was the revenue hypothesis, what did the downstream CRM data show, and what is the recommended next action? Include both the platform metrics and the CRM outcome in every report so readers can see the full picture. Capture inconclusive tests in the log with a note on what would need to change for the test to produce a clear signal. A testing log that records what was learned from both positive and negative results becomes an institutional knowledge asset that compounds the programme’s effectiveness over time.


