Conducting Rapid Google Ads Experiments for SaaS Without Pipeline Risk
Learn how to run fast Google Ads experiments for SaaS while protecting your sales pipeline and budget efficiency.

You want to move faster. Test more. Stop guessing which bid strategy, ad copy, or audience configuration is actually moving deals. But your Google Ads campaigns are generating pipeline your sales team depends on, and every time you change something, you’re taking a risk you can’t fully quantify.
This is the central tension of rapid Google Ads testing for SaaS: the urge to experiment quickly sits in direct conflict with the need to protect the demand capture that keeps the business running.
The good news is you do not have to choose between speed and safety. With the right structure, B2B SaaS teams can run continuous, meaningful experiments without disrupting core demand capture or exposing the pipeline to unnecessary variance. What it requires is a framework built around isolation, sequencing, and honest success criteria.
Why Generic Experimentation Advice Breaks Down for B2B SaaS
Most guidance on Google Ads A/B testing is written with e-commerce in mind. It assumes high conversion volumes, short attribution windows, and a single decision-maker completing a transaction in one session. B2B SaaS accounts operate in fundamentally different conditions.
Sales cycles in B2B SaaS average around 84 days. An experiment evaluated at day 14 is measuring early-funnel activity only. The ad copy or landing page that looks like a winner based on form fill volume at day 14 may have poor MQL-to-SQL conversion once the data matures. Teams that declare winners prematurely often bake false conclusions into their account structure, creating compounding problems downstream.
Volume compounds the issue. A SaaS campaign generating 200 form fills per month may produce only 40 SQLs and fewer than 10 opportunities. At these volumes, standard statistical significance thresholds require longer run times than most marketing teams are prepared to tolerate. Cutting tests short introduces the same noise as not testing at all.
The third problem is conversion signal quality. If Smart Bidding is trained on form fills rather than SQLs or opportunities, every experiment is measuring the wrong outcome. The “winning” variant is the one that generates more form submissions, not more qualified pipeline. That is a meaningful difference when the cost per SQL for B2B SaaS can sit anywhere between £70 and £1,200 depending on segment and ACV.
None of this means experimentation is impractical for SaaS. It means the methodology needs to account for these conditions from the start.
The Foundation: Using Google’s Native Experiments Tool Correctly
Before addressing what to test, it is worth being precise about how to run experiments structurally. Manual campaign duplication is not a valid testing method for B2B SaaS. When you clone a campaign and run the two versions in parallel, you introduce time-of-day bias, audience overlap, and inconsistent auction conditions. The comparison becomes unreliable.
Google’s native Experiments feature (found under Campaigns > Experiments in the Google Ads interface) splits traffic between the base campaign and a variant using the same auction, the same budget pool, and consistent attribution logic. Statistical significance testing is applied automatically. This is the only method that produces defensible conclusions for accounts with limited conversion volume.
For B2B SaaS specifically, a 70/30 traffic split is usually more appropriate than the default 50/50. Allocating 70% of traffic to the proven base campaign protects pipeline while giving the variant enough volume to accumulate meaningful data. For higher-risk tests, such as bidding strategy changes, the split can move to 80/20 initially and widen once early indicators look stable.
Cookie-based splits are preferable to search-based splits in B2B contexts. A buying committee member who sees the control version in their first search session will see the control version in all subsequent searches. This avoids the contamination risk of a single user experiencing both variants during a long evaluation cycle.
Protecting Core Demand Capture During Experimentation
The practical answer to minimising pipeline risk in Google Ads is to separate what you test from what you rely on.
Core demand capture campaigns are your high-intent, branded, and competitor terms. These are the campaigns closest to closed-won revenue. They should not be the primary site of experimentation. Changes here carry the highest risk relative to the potential learning because the downside of disrupting a high-converting campaign outweighs the marginal insight gained.
Experimentation belongs primarily in non-branded search campaigns and, where volume allows, in mid-funnel demand generation. These campaigns contribute to pipeline but are not the single thread holding revenue together. Running experiments here lets you accumulate learning without putting your most efficient demand capture at risk.
A useful budget allocation model: treat roughly 10-15% of campaign spend as the experimentation envelope. This is not a hard rule, but it provides a mental boundary. Tests running within this allocation carry contained downside. If a variant underperforms significantly, the impact on overall pipeline is bounded.
The other protection mechanism is setting clear stopping criteria before you launch. Define in advance what “underperforming significantly” means. A conversion rate drop of more than 40% within the first seven days is a reasonable early-exit signal for most accounts. Without predetermined criteria, teams either let bad tests run too long or end useful ones prematurely based on noise.
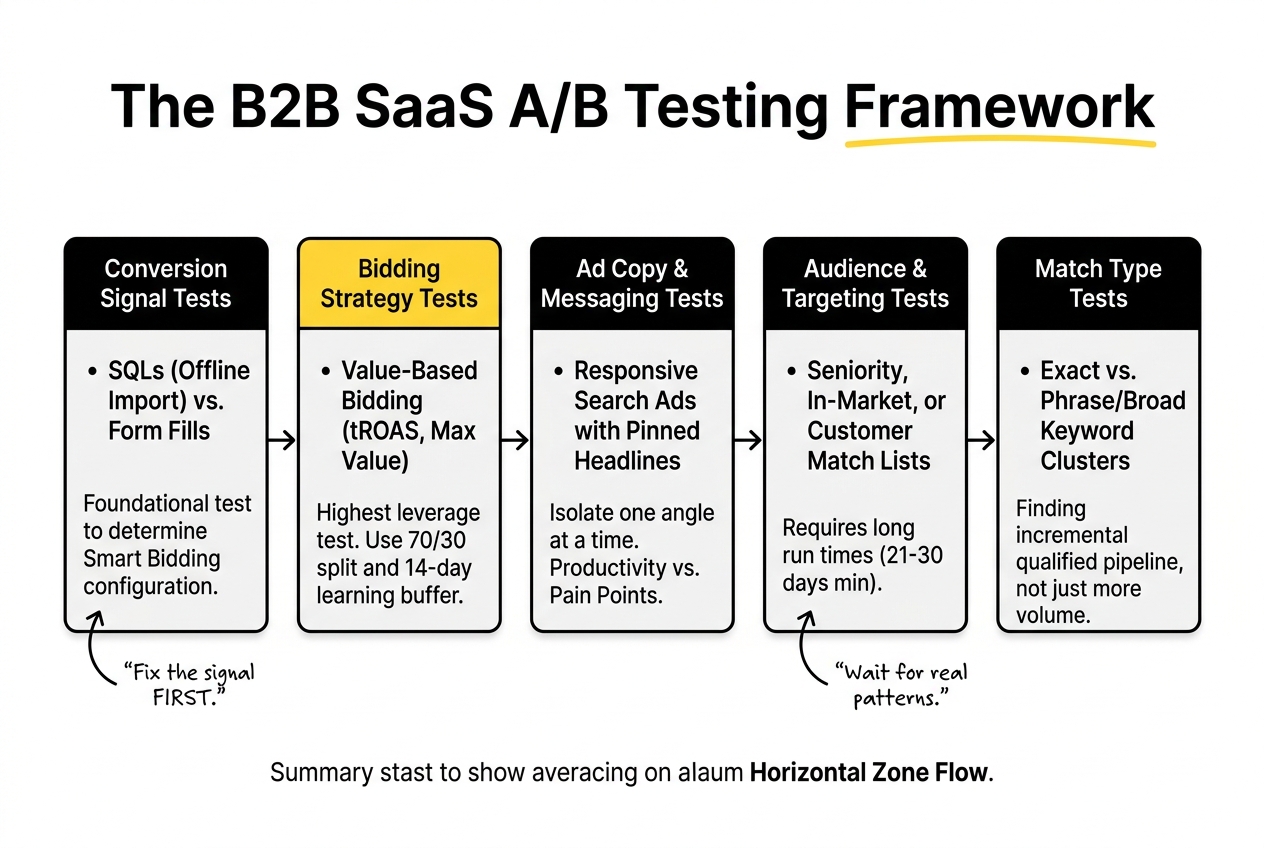
What to Test, in What Order
Not all experiments carry equal pipeline risk or equal learning potential. Sequencing tests by category reduces the chance of compounding errors and makes results easier to interpret.
Conversion signal tests should come first for accounts that have not yet connected CRM data to Google Ads. Testing whether optimising for SQLs (via offline conversion import) versus form fills produces different lead quality is foundational. The outcome of this test determines how Smart Bidding should be configured for all subsequent experiments. Until this question is answered, bidding tests are measuring the wrong thing.
Bidding strategy tests come next. Moving from manual CPC or Target CPA to value-based bidding (Maximize Conversion Value or Target ROAS with tiered conversion values) is the highest-leverage experiment most SaaS accounts can run. The structural approach: split a high-intent search campaign 70/30, run the control on the existing bidding strategy, and apply value-based bidding to the variant. Allow a 14-day learning buffer before evaluating results, as Smart Bidding needs time to stabilise before you can draw conclusions.
Ad copy and messaging tests are lower-risk but require careful variable isolation. Test one messaging angle at a time using Responsive Search Ads with pinned headlines. Pinning forces Google to serve specific copy rather than mixing variants, which makes comparison clean. Common angles worth testing in B2B SaaS: productivity-framed claims versus pain-point framing, ACV-relevant proof points versus feature descriptions, and social proof (customer counts, recognisable logos) versus outcome claims.
Audience and targeting tests come after copy is stable. Testing seniority-based targeting, in-market audience segments, or customer match lists is genuinely valuable but requires longer run times. Audience tests typically need 21-30 days minimum before patterns emerge.
Match type tests are worth running for accounts leaning heavily on exact match. Testing broad match for specific keyword clusters against phrase or exact alternatives reveals whether the algorithm’s expanded matching is producing incremental pipeline or inflating volume with low-quality signals. In most B2B SaaS accounts, phrase match holds a conversion rate advantage while broad match wins on volume. The question is always which produces more qualified pipeline at acceptable cost, not which generates more clicks.
Setting Success Metrics That Hold Up
The most common experimentation failure in B2B SaaS is measuring the wrong thing at the wrong time. Tracking CTR and form fill rate at two weeks and calling it a result is not experimentation. It is noise confirmation.
The success metrics that actually matter are:
- MQL-to-SQL conversion rate by variant -- This requires CRM integration but is the only metric that distinguishes pipeline-generating traffic from volume that wastes sales capacity.
- Cost per SQL by variant -- Not cost per lead. SQLs are the minimum threshold for a meaningful signal.
- Time-to-SQL -- Some ad copy and audience combinations produce faster-moving leads. This matters for sales velocity even if the total SQL volume is similar.
- Pipeline value attributed by variant -- Achievable with offline conversion import and deal value data from HubSpot or Salesforce. This is the most direct measure of experiment impact.
For accounts without CRM integration, form fill volume and conversion rate are acceptable interim proxies, but they must be treated as directional rather than conclusive. Any decision made on form fill data alone should be confirmed with a follow-up check of downstream quality two to three months later.
On confidence thresholds: Google Ads defaults to flagging significance at 80% confidence. For B2B SaaS, where false positives are expensive, 95% confidence should be the target. This means accepting more inconclusive results, but it also means fewer decisions based on noise.
Minimum Test Durations for B2B SaaS Contexts
Ad copy tests with meaningful conversion volume: 4-6 weeks minimum.
Bidding strategy tests: 6 weeks minimum, with a two-week learning buffer before any evaluation.
Audience and targeting tests: 4-8 weeks, longer for low-volume accounts.
Major campaign structure tests: 8-12 weeks.
These durations feel long compared to e-commerce timelines, but they reflect the reality of B2B attribution windows and conversion volumes. Running tests shorter than these thresholds produces results that look meaningful but often reverse when given more time.
If a test is producing catastrophically poor results, such as a conversion rate more than 50% below baseline in the first seven days, it is reasonable to pause early. Outside of this early-exit scenario, resist the pressure to call results before the minimum duration has elapsed.

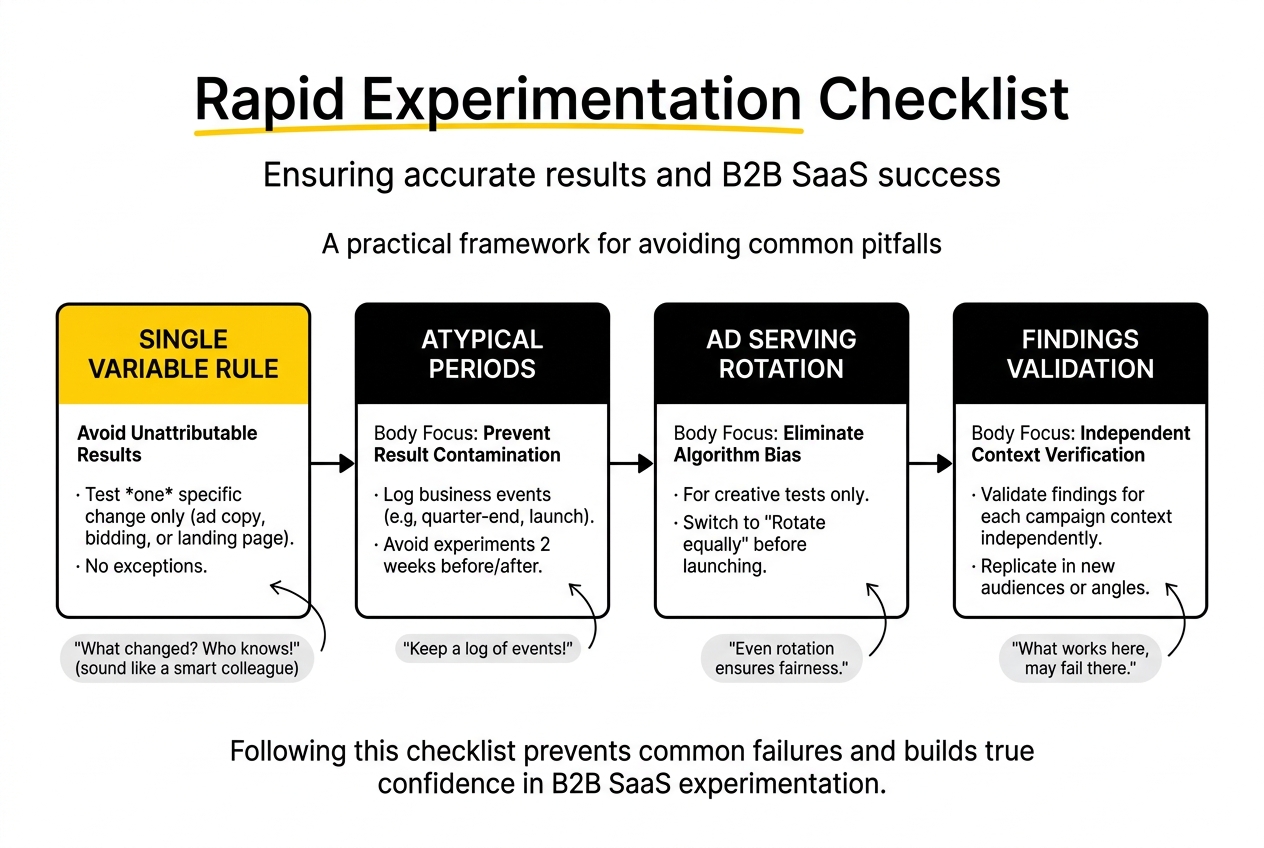
A/B Testing in Digital Marketing for SaaS: Common Pitfalls
Several patterns consistently undermine experimentation programmes in B2B SaaS accounts.
Testing multiple variables simultaneously is the most common. Changing ad copy, landing page, and bidding strategy in the same experiment produces a result that is unattributable. You know something changed. You do not know what. The rule is one variable per experiment, without exception.
Running experiments during atypical periods contaminates results. Testing across a quarter-end close, a major product launch, or a seasonal demand spike introduces confounding variables that cannot be separated from the experimental variable. Keep a log of business events and avoid launching new experiments in the two weeks surrounding them.
Optimising ad serving to “optimised” rather than “rotate equally” during creative tests introduces algorithm bias. If Google is serving the better-performing ad more frequently, it is doing the optimisation work the experiment is supposed to measure. For any test involving ad copy, switch to even rotation before launching.
Treating a positive result in one campaign as a universal truth creates false confidence. A messaging angle that works in a competitor-targeting campaign may not work in a branded campaign or a mid-funnel awareness context. Validate findings in each campaign context independently before applying them account-wide.
Transparent Reporting for Experiment Results
Quick Google Ads tests for SaaS with no pipeline risk require stakeholder trust. Stakeholders who do not understand what an experiment is testing, how long it will run, and what constitutes a result will intervene before tests mature. This is one of the most common causes of inconclusive experiments.
A simple experiment log format prevents this. For each test, record: the hypothesis, the variable being tested, the baseline metric, the success threshold, the minimum run time, and the outcome. Sharing this log with leadership before tests launch aligns expectations and creates a clear communication structure for results.
When experiments are inconclusive, say so clearly rather than attributing ambiguity to external factors. An inconclusive result is not a failure. It is evidence that the effect size was smaller than the test could detect, or that the variable does not have the impact assumed. That is useful information.
When experiments produce results that conflict with intuition, investigate before discarding them. A result that shows worse form fill volume but better downstream SQL quality is not a bad result for a B2B SaaS account. It may be the most important finding in the entire testing programme.
From Experiment to Campaign Change
Fast-tracking Google Ads experiments while safeguarding your pipeline requires a clear process for what happens after an experiment ends.
If the variant outperforms the control at 95% confidence, apply the change to the base campaign using Google’s one-click apply function. This preserves the campaign’s learning history rather than requiring a cold restart.
If the variant underperforms, document the finding, discard the experiment, and update the hypothesis log. The failed test has narrowed the space of likely improvements. That is progress.
If the result is inconclusive, do not apply the change. Run the test for longer if budget allows, or redesign the test with a larger expected effect size. Applying an inconclusive result as if it were a win is how SaaS accounts accumulate a series of small, individually defensible decisions that collectively degrade performance.
Working with a b2b saas ppc agency that maintains a structured experiment programme typically produces more consistent pipeline improvement than ad hoc testing, primarily because the sequencing and documentation disciplines are built into the engagement rather than left to individuals who have competing priorities.
If you are building this capability internally, the structural requirements are modest: a functioning offline conversion import, a consistent experiment log, and a standing commitment to minimum test durations regardless of internal pressure to move faster.
Frequently Asked Questions
What are the best practices for conducting rapid Google Ads experiments in the SaaS sector?
Use Google’s native Experiments feature rather than duplicating campaigns manually. Test one variable at a time, set a minimum run duration of four to six weeks for most test types, and target 95% confidence before declaring a winner. Protect core demand capture campaigns from experimentation by focusing tests on non-branded search campaigns. Connect CRM data so you can measure SQL impact rather than just form fill volume.
How can B2B marketing managers minimise pipeline risk while experimenting with Google Ads?
Use a 70/30 or 80/20 traffic split that keeps the majority of traffic on your proven base campaign. Limit experiments to 10-15% of total account spend. Define early-exit criteria before launching, so you can stop underperforming tests quickly without waiting for formal results. Avoid experimenting on branded and high-intent competitor campaigns where disruption risk is highest relative to learning potential.
What metrics should be tracked to evaluate the success of Google Ads experiments for SaaS?
The primary metrics are MQL-to-SQL conversion rate by variant, cost per SQL, and pipeline value attributed. Form fill volume and conversion rate are acceptable proxies for accounts without CRM integration, but treat them as directional rather than conclusive. For bidding tests, evaluate cost per opportunity rather than cost per lead. Time-to-SQL is a useful secondary metric for assessing pipeline velocity.
How can A/B testing improve lead quality in Google Ads campaigns for SaaS?
By isolating the variables that influence who clicks and who converts. Testing different messaging angles, seniority-based audience targeting, and lead qualification mechanisms (form friction, landing page messaging, CTA framing) surfaces which configurations attract ICP-aligned buyers versus high-volume but low-quality traffic. The key is connecting test results to downstream quality data via CRM integration rather than measuring only at the point of form submission.
What budget considerations should be made when running Google Ads for SaaS?
Treat 10-15% of campaign spend as the experimentation envelope. Run experiments at reduced traffic splits (70/30) to contain downside risk. Avoid making budget changes to either the base or variant campaign while an experiment is running, as this introduces variables that compromise the comparison. Bidding tests specifically require a stable budget period during the learning phase, typically the first two weeks.
How can transparent reporting enhance decision-making in Google Ads campaigns?
A documented experiment log, shared with stakeholders before tests launch, prevents interference with tests that have not yet matured. When everyone understands the hypothesis, the variable being tested, and the minimum run time, premature calls become less likely. Consistent documentation also builds a body of institutional knowledge about what works in the specific account, which compounds over time in ways that ad hoc testing does not.
What strategies can be employed to optimise Google Ads performance in a competitive landscape?
Prioritise variable isolation and sequential testing over trying to make many improvements simultaneously. Focus experimentation on conversion signal quality first, then bidding strategy, then ad copy, then audiences. Use the results of each experiment to inform the next one rather than running tests in parallel. Accounts that run one well-structured test per month consistently outperform accounts that run three poorly structured tests per month.
How can SaaS companies ensure core demand capture while experimenting with paid search?
Separate experimentation from core demand capture structurally. Branded, high-intent, and competitor-term campaigns should run on proven settings with change-management discipline, not as active experiment sites. Experimentation belongs in non-branded search and mid-funnel campaigns where the risk-to-learning ratio is more favourable. The exception is bidding strategy tests, which can and should eventually be applied to core campaigns, but only after validation in lower-risk campaign contexts.
What are common pitfalls to avoid when running Google Ads experiments for SaaS?
Testing multiple variables simultaneously. Ending tests before minimum duration thresholds. Using “optimised” ad serving instead of equal rotation during creative tests. Running experiments during atypical business periods like quarter-end. Measuring success on form fill volume rather than SQL quality. Applying results from one campaign context as universal truths without validating in other contexts.
How can marketers quickly implement changes based on Google Ads experiment results?
Google’s one-click apply function transfers winning experiment settings to the base campaign without resetting its learning history. This is the correct method; do not rebuild the campaign manually. For changes that require more complex implementation, such as a fundamental restructure of campaign architecture, build the new structure as a separate campaign, allow it to establish a learning period, and phase budget across gradually rather than making a hard switch.
If you are building an experimentation programme from scratch and want to pressure-test your current setup, this is the kind of work we do regularly with SaaS teams. Worth a conversation if you are at that point.


