Understanding SaaS PPC Trial Campaigns: Successes and Pitfalls
Learn how SaaS teams can design and measure PPC trial campaigns to prove channel fit, avoid misleading signals, and make confident decisions about scaling paid search.

You run a 60-day paid search trial. Clicks come in. Form fills follow. The platform dashboard looks healthy. Then the CFO asks how much qualified pipeline the spend actually created, and the answer is somewhere between “unclear” and “not much.” The trial proved something, just not what you needed it to prove.
This is the central problem with paid media trial campaigns in B2B SaaS. The mechanics of a PPC trial are straightforward. The interpretation is not. When trial results genuinely indicate channel fit, the path to scaling is clear. When they mislead, doubling down on spend becomes an expensive mistake that is difficult to unpick six months later.
This article sets out what signals to trust, which metrics tend to flatter the wrong things, and how to structure a trial so the data it produces is worth acting on.
What a PPC Trial Campaign Is Actually Testing
Before any measurement discussion, it is worth being precise about what a trial campaign is designed to prove.
A paid search trial in SaaS is not primarily a test of whether Google Ads or LinkedIn Ads “works.” It is a test of whether paid demand capture can acquire customers from your ICP at a unit economics ratio that holds up over time. That distinction matters because many trial campaigns are designed, executed, and judged against the wrong question.
A trial that generates 40 MQLs in 60 days has answered: “Can we generate form fills from paid search?” It has not answered: “Can we generate pipeline that closes at a cost that fits our LTV:CAC targets?” Those are different questions, and the second one is the only one that matters in a board review.
A well-designed SaaS PPC trial tests three things specifically:
- Audience quality: Does paid search reach the right buying personas at the right companies, or does it pull in a wider audience that looks interested but does not fit the ICP?
- Conversion architecture: Do the landing pages, offers, and call-to-action choices convert intent into demos or trials at a rate that makes the economics work?
- Attribution baseline: Is the tracking reliable enough to connect ad spend to pipeline, even directionally?
If the trial does not have clear answers to all three by the end of the period, the data produced is not sufficient to justify a scaling decision either way.
Common SaaS Trial Campaign Success Metrics: What Actually Signals Fit
Most teams enter a trial tracking the wrong metrics at the top of the funnel and the right ones too far down the funnel for them to be actionable within the trial window.
Metrics that genuinely signal fit:
Cost-per-qualified-opportunity (CPQO). Not cost-per-lead, not cost-per-MQL. The metric that matters is how much it costs to generate a sales opportunity that meets your qualification criteria. MQL volume can look strong while CPQO is unsustainable, because ICP fit and sales qualification are filters that only activate downstream. If your paid search leads are not converting to SQLs at a rate comparable to your other acquisition channels, that is a meaningful signal in itself.
MQL-to-SQL conversion rate from paid traffic. This cohort-level comparison is one of the most useful data points a trial can produce. If paid search MQLs convert to SQLs at 10% versus 18% from organic, the quality gap is a structural problem, not a budget problem.
CAC payback trajectory. If the trial period captures enough closed-won data, even a small sample provides directional evidence on whether the channel’s cost structure can support your payback period target. The current median paid CAC for B2B SaaS sits at roughly $619 per customer, against an average CAC of $2.00 for every $1 of new ARR acquired. A trial that runs above those benchmarks by a significant margin without a clear quality differential warrants scrutiny.
Metrics that can mislead:
Click-through rate and conversion rate in isolation. A high CTR signals relevance to the search query. It does not signal relevance to your buying committee. A 6% CTR on a broad keyword cluster may feel like validation. If the clicks are from junior users at SMBs outside your ICP, it is not.
Lead volume without cohort tagging. Without CRM tagging that links every lead back to the specific campaign, ad group, and keyword that drove it, trial data becomes an average of everything, and averages in paid search conceal more than they reveal.
Branded search performance. Branded campaigns look excellent in every trial because CPCs are low, conversion rates are high, and the audience is already warm. A trial that over-indexes on branded terms has primarily measured whether people who already know you will click an ad. That is useful to know, but it does not validate paid demand capture from cold audiences.
When Paid Media Trial Campaigns Demonstrate Suitability
A trial campaign genuinely demonstrates channel fit when a specific set of conditions are met together, not individually.
The ICP match is confirmed in the CRM, not just the platform. When trial leads are tagged and tracked through to qualification stage, and the ICP match rate from paid search is comparable to your best-performing existing channels, the audience targeting is working. This is the first gate.
Pipeline has been created, not just leads. Fit is confirmed when paid search activity produces opportunities that enter the pipeline and progress through stages at a velocity comparable to non-paid leads. If paid leads stall at unqualified demo stage consistently, the issue is either audience quality or the offer, and neither justifies scaling spend.
Attribution is stable and directional. The trial has produced enough closed-loop data to connect spend to outcomes, even with partial attribution. This does not mean perfect attribution: perfect attribution in B2B SaaS with six-month sales cycles and multiple decision-makers does not exist. It means the signal is consistent and directional enough to make a budget decision with appropriate confidence.
Unit economics hold at trial budget. If the trial was run at a meaningful budget (typically at minimum a few thousand pounds per month in total spend), and the CPQO at trial scale fits within the acceptable CAC range for your LTV:CAC target of 3:1 or better, scaling spend is a logical next step. The risk is that unit economics that hold at £5,000 per month can deteriorate significantly at £30,000 per month as you exhaust high-intent keyword inventory and bid competition increases.
When all four of these conditions are present, the case for scaling is credible. When only one or two are present, the trial has proved partial fit at best.
When SaaS PPC Trial Campaigns Mislead: Common Pitfalls in SaaS PPC Advertising
Several structural factors cause trial campaigns to produce results that look better than the underlying reality.
Over-reliance on last-click attribution. In a 60-day trial window, last-click attribution assigns credit to paid search for any conversion that clicked a paid ad near the end of a multi-touch journey. A buyer who spent three months reading content, attending a webinar, and following a peer recommendation may convert via a branded search ad at the end of that journey. Last-click attributes the conversion entirely to paid search. The trial looks like it worked. What it actually captured was demand that other channels built.
This is not a theoretical problem. Many B2B SaaS teams operate on attribution data that is structurally broken due to a combination of last-click defaults, iOS tracking limitations, and cookie deprecation. Budget decisions made on top of broken attribution will optimise toward channels that look good on paper rather than channels that are actually driving pipeline.
Running the trial at insufficient budget to exit the learning period. Google Ads’ automated bidding requires meaningful conversion volume before it can optimise effectively. A trial run at too low a budget across too many campaigns produces data that reflects the learning period, not the steady state. The signal quality improves significantly once campaigns have accumulated enough conversion data for the platform’s algorithms to calibrate. Many trial campaigns are assessed, and scaled or killed, before this point is reached.
Testing in a period that is not representative. A trial run across a quarter-end, a product launch period, or an unusually high or low-intent search period will produce results that do not reflect normal conditions. This is easy to overlook when the pressure to produce results quickly is high.
Conflating trial sign-up volume with fit. For SaaS products with a freemium or self-serve trial model, PPC can generate trial sign-ups efficiently. But trial sign-ups and trial activation are different metrics, and activation is what connects to paid conversion. According to ChartMogul’s 2026 study of 200 software products, opt-in free trial conversion rates average 8.9%, with significant variation by product category and trial model. A trial campaign that generates sign-up volume without tracking activation and conversion to paid is measuring only the first step of a multi-step funnel.
Treating branded and non-branded performance as a single figure. A campaign that blends branded and non-branded performance into a single reported CPA will almost always look more efficient than it is. Non-branded demand capture, which is the harder and more important channel to validate, is typically subsidised by branded performance in blended reporting. Separating these cohorts is not optional in a meaningful trial.

Budget Allocation for PPC Campaigns: How Spending Structure Affects Trial Validity
How the trial budget is distributed across campaign types, keywords, and stages has a material effect on what the trial can prove.
A trial that allocates 80% of spend to branded and competitor terms and 20% to category and problem-aware terms will validate demand capture but not demand creation. That is a legitimate finding, but it is a limited one. If the goal is to determine whether paid search can scale acquisition from cold audiences, the majority of trial spend needs to be in non-branded, high-intent keyword categories.
A useful allocation framework for a B2B SaaS trial:
- 50-60% to high-intent non-branded keywords directly tied to the problem your product solves
- 20-30% to competitor terms (to understand cost-of-entry in your specific market)
- 10-20% to branded terms (to establish a baseline, not to dominate the trial results)
The total budget needs to be sufficient to generate enough conversion events for statistical confidence. Running a 60-day trial at £2,000 total spend across three campaigns will produce data that is too thin to act on reliably. That is not a failure of the channel; it is a structural problem with the trial design.
Attribution in SaaS Marketing: Getting the Measurement Right Before You Scale
Attribution is always incomplete in B2B SaaS. The goal is not to solve it; the goal is to build a measurement structure that is consistent and honest about its limitations.
Several foundational elements need to be in place before a trial produces usable data.
Offline conversion imports. If your funnel includes sales-assisted demos or enterprise discovery calls, those qualification events need to be imported back into the ad platform. Optimising toward form fills or trial sign-ups when the actual revenue event is a qualified demo will consistently drive volume at the expense of quality.
UTM consistency throughout the CRM. Every lead from a paid trial campaign needs to carry its source, campaign, and keyword identifiers through to the CRM record. Without this, post-trial analysis requires manual cross-referencing that is time-intensive and error-prone. This sounds obvious; it is frequently missing.
A consistent attribution model applied across the trial period. Switching attribution models mid-trial invalidates comparison data. Whether you use first-touch, last-touch, or a position-based model matters less than applying it consistently so the data from week one is comparable to week eight.
The broader point is that attribution will never confirm with certainty that paid search caused a deal to close in a B2B SaaS business with a six-month sales cycle and a seven-person buying committee. What attribution can do is provide consistent, directional evidence that specific campaign activity correlates with pipeline creation at a cost that fits your CAC targets. That is sufficient to make a scaling decision. Waiting for perfect attribution before acting is waiting indefinitely.

When to Scale SaaS PPC Campaigns: The Decision Framework
Scaling a paid search programme based on trial data requires specific criteria to be met, not just positive-looking numbers.
Scale when:
- Non-branded keywords are generating SQLs at a CPQO that fits within your target CAC range
- MQL-to-SQL conversion rates from paid traffic are within 20% of your best organic or referral channel
- The trial has run for at least 60 days with sufficient weekly conversion volume for bidding algorithms to have exited the learning period
- Attribution infrastructure is in place to track outcomes through to qualified pipeline, not just form fills
- Budget has been tested at a level sufficient to surface how cost-per-opportunity moves with spend increases
Do not scale when:
- Trial results are dominated by branded performance
- MQL volume looks strong but SQL conversion is significantly below other channels
- Attribution is limited to platform-reported conversions without CRM cross-referencing
- The trial ran at too low a budget to produce statistically meaningful data
- The trial period overlapped with an atypical demand event (product launch, competitor exit, promotional period)
The overlap guardrail matters here: the question of when to scale paid search after achieving product-market fit is a separate decision that involves your operating model, team capacity, and channel portfolio. This article is specifically about how to read trial data correctly, not how to build the broader post-PMF acquisition motion. Our saas paid media agency page covers what that looks like from an operational standpoint.
Practical Steps Before Drawing Conclusions from a Trial
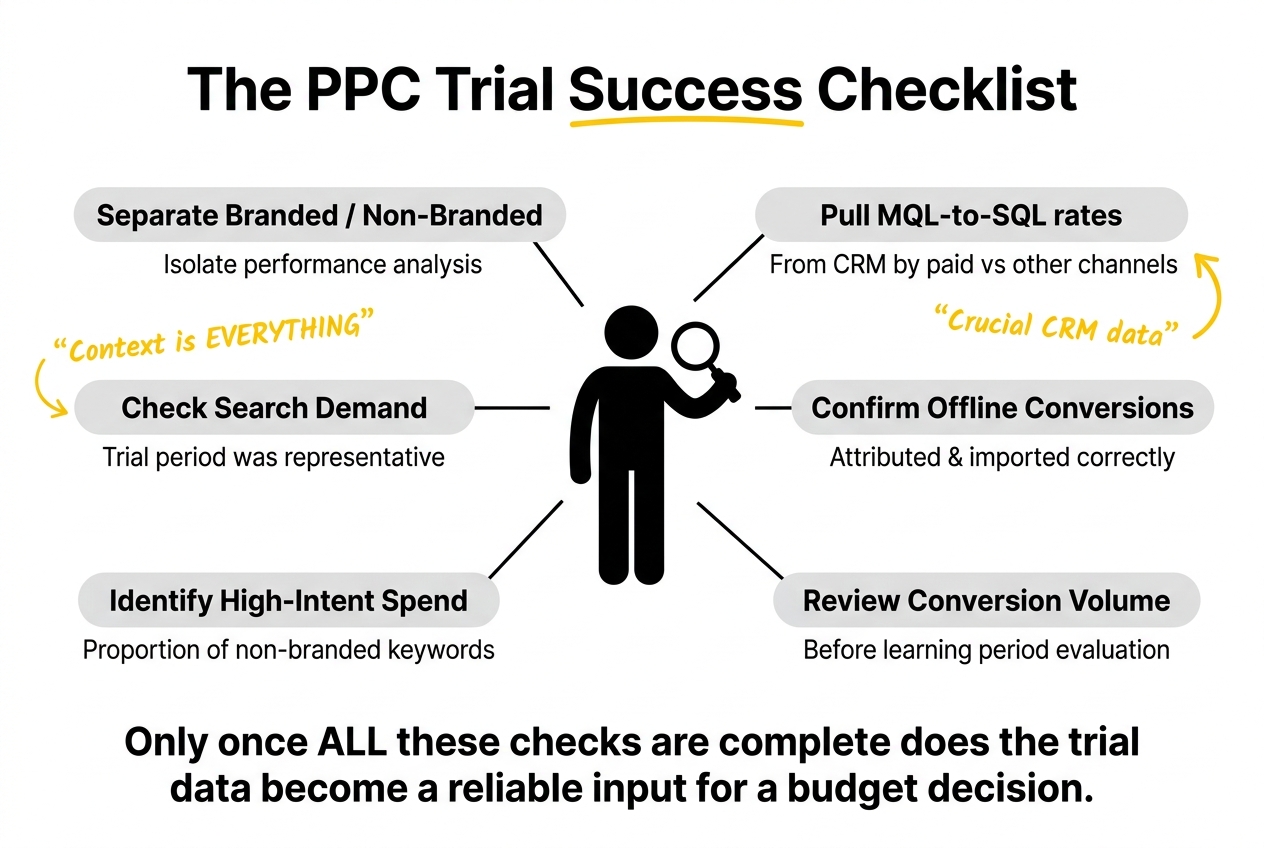
Before deciding whether trial results justify scaling, run through this checklist.
Before drawing any conclusions:
- Separate branded and non-branded performance in your analysis
- Pull MQL-to-SQL conversion rates from the CRM by source (paid vs other channels)
- Confirm that offline conversions are imported and attributed correctly
- Check whether the trial period was representative of normal search demand
- Identify the proportion of spend that went to high-intent non-branded keywords
- Review whether the learning period had sufficient conversion volume before the evaluation window closed
Only once these checks are complete does the trial data become a reliable input for a budget decision.
Frequently Asked Questions
How can SaaS companies determine the effectiveness of their PPC trial campaigns?
Effectiveness requires closed-loop measurement: tracking leads from ad click through to qualified opportunity and, ideally, to closed-won revenue. At minimum, campaigns should be tagged with UTM parameters that carry through to the CRM, and offline conversions should be imported back into the ad platform. Reporting on platform-side conversion data alone produces figures that tend to overstate performance because they cannot account for lead quality downstream.
What are the key performance metrics to track for SaaS PPC campaigns?
The metrics that matter in B2B SaaS are cost-per-qualified-opportunity, MQL-to-SQL conversion rate by source, CAC payback period, and LTV:CAC ratio. Platform metrics like CTR, CPC, and impression share are operational indicators, not performance proof points. They tell you how the campaign is functioning; they do not tell you whether the channel is worth the investment.
How does budget allocation impact the success of PPC campaigns for SaaS companies?
Budget allocation determines what the trial can actually test. A budget that concentrates spend on branded terms validates demand capture from warm audiences, not the channel’s ability to acquire new customers. Insufficient total budget means bidding algorithms never exit the learning period, which produces data that reflects an unstable optimisation state rather than steady-state performance. Both issues are common reasons why trial results mislead.
What common pitfalls should SaaS marketers avoid when interpreting PPC trial results?
The four most common pitfalls are: relying on last-click attribution that inflates paid search credit; blending branded and non-branded performance into a single reported CPA; assessing results before the learning period has completed; and treating MQL volume as a proxy for pipeline quality. Each produces trial conclusions that look credible but do not hold up when connected to revenue outcomes.
How can attribution models influence the evaluation of PPC campaign success in SaaS?
Attribution models determine which touchpoints receive credit for a conversion. Last-click models favour the final touchpoint, which in a multi-channel B2B journey is often a branded search. First-click models favour awareness channels that may not have closed the deal. No model is objectively correct for B2B SaaS. What matters is consistency: applying the same model throughout the trial period so results are comparable, and being honest that the model is a framework for decision-making, not a factual account of causality.
What strategies can SaaS companies use to optimise their PPC campaigns for better ROI?
The highest-impact optimisation in B2B SaaS PPC is typically improving what happens downstream from the click: landing page relevance, offer clarity, and lead qualification speed. Optimising bids and keywords while the conversion architecture is weak produces diminishing returns. Importing offline conversions so the bidding algorithm optimises toward qualified demos rather than form fills is consistently one of the highest-leverage technical changes a SaaS team can make.
When should SaaS companies consider scaling their PPC efforts based on trial campaign results?
Scale when non-branded campaigns are producing SQLs at a CPQO within your CAC targets, MQL-to-SQL rates from paid traffic are competitive with other channels, and attribution infrastructure is stable enough to track outcomes through to pipeline. Do not scale on the basis of platform metrics alone, or when trial results are dominated by branded performance, or when the trial period was too short or underfunded to produce reliable signal.
How can SaaS marketing leaders defend their PPC budget decisions using trial campaign data?
The strongest budget defence is a closed-loop CAC argument: here is how much we spent, here is the pipeline it created, here is how that pipeline converts, and here is the projected CAC relative to our LTV target. This requires attribution infrastructure to be in place before the trial begins. A retrospective attribution exercise is possible but much weaker, because the data integrity challenges are harder to resolve after the fact.
What role does audience targeting play in the success of SaaS PPC campaigns?
Audience targeting determines whether paid search reaches the buying committee or a wider population that resembles them superficially. For B2B SaaS, this means layering in company size, industry, and job function signals alongside keyword intent. A campaign that targets the right keywords but reaches the wrong job titles at the wrong company sizes will produce MQL volume that fails at qualification. Reviewing who is actually in the CRM from paid campaigns, not just who clicked, is the most direct way to assess targeting quality.
How can SaaS companies identify misleading metrics in their PPC trial campaigns?
The clearest indicator of misleading metrics is a gap between platform-reported conversions and CRM-confirmed pipeline. If Google Ads reports 80 conversions and your CRM shows 12 leads from paid search, the conversion tracking is counting the wrong events. A secondary indicator is a meaningful performance gap between branded and non-branded campaigns that is only visible when the two are separated. Most misleading trial results stem from measurement problems, not channel problems.
If you are working through a trial campaign and the data is not yet telling a clear story, we are happy to take a look at the attribution setup and measurement framework. This is the kind of diagnostic work we do regularly with SaaS teams before any scaling decision is made.


