Why Your SaaS PPC Tests Aren’t Moving the Needle: Diagnosing False Experiments and Bad Signals
Learn why SaaS PPC tests fail to move the needle, and how to fix false experiments, weak hypotheses, and bad optimisation signals.

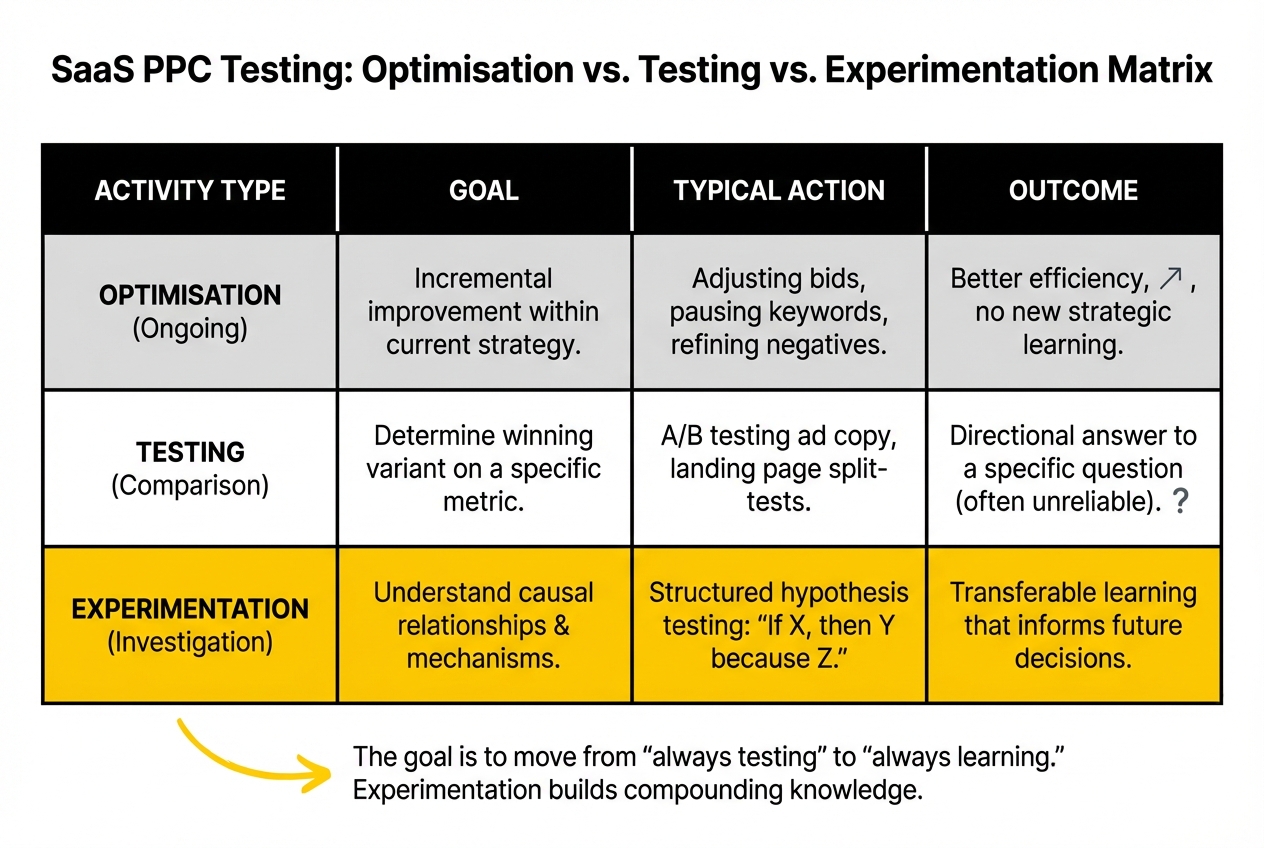
The Three Things People Call Testing (That Are Not All the Same)
Before diagnosing why tests fail, it helps to separate three activities that are routinely conflated in PPC account management.
Optimisation is the ongoing adjustment of account variables based on observed performance: adjusting bids, pausing underperforming keywords, updating negative keyword lists, improving quality scores. It produces incremental improvement within the current strategy. It does not produce learning about what would happen under a different strategy. Optimisation is necessary and valuable, but it is not experimentation.
Testing is a controlled comparison of two known variants to determine which performs better on a defined metric. A/B testing ad copy, comparing landing pages, split-testing bid strategies. Testing produces a directional answer to a specific question, but only if the test is designed correctly and run long enough to produce a reliable result. Most PPC testing in B2B SaaS accounts is designed incorrectly.
Experimentation is the structured investigation of a hypothesis about causal relationships: if we change X, Y will happen because of Z. Real experimentation specifies the mechanism, not just the outcome. It produces transferable learning that informs future decisions beyond the specific test. Experimentation requires more rigour than optimisation or testing, but produces the compounding returns that neither of the other two can deliver.
Most accounts that describe themselves as "always testing" are optimising and occasionally running underpowered tests. Very few are experimenting in the meaningful sense. The gap between these three activities is why six months of "testing" produces no scalable learning.
Why Most SaaS PPC Tests Are Underpowered
Statistical power is the probability that a test will detect a real effect if one exists. A test with low power is likely to miss real effects and may produce false positives from random variation. In B2B SaaS PPC, low power is the default condition, not the exception.
The reason is conversion volume. Mid-market B2B SaaS accounts often generate 20-60 conversions per month from paid search. For a test to detect a 15% improvement in conversion rate with 80% power at 95% confidence, it typically needs several hundred conversions per variant. At 30 conversions per month total, a two-variant test would take a year to reach that sample size. In practice, tests get called after two or four weeks regardless of whether they have reached any reliable conclusion.
The consequences are predictable. A test that ends at 40 total conversions has very wide confidence intervals. The result can swing significantly from week to week based on a handful of conversions. A variant that appears to be winning by 20% at week three may be losing by the same margin at week six, not because anything changed, but because the sample was too small to distinguish a real effect from random variation.
This does not mean B2B SaaS teams should stop running tests because traffic is too low. It means the tests should be designed differently: larger effect sizes targeted (changes likely to produce 30%+ differences rather than 5% differences), longer run times built into the plan before the test starts, and Bayesian approaches considered for environments where 95% frequentist confidence is not achievable in a reasonable timeframe. As Understory’s B2B SaaS testing research notes, using 85-90% confidence thresholds for directional decisions is more appropriate than requiring the 95% threshold designed for high-traffic e-commerce environments.
The practical implication: if your account cannot support a properly powered test of the change you want to make, do not run the test in its current form. Either increase traffic to the tested element, accept a lower confidence threshold with explicit acknowledgment that the result is directional, or focus testing resources on higher-stakes changes where the expected effect size is large enough to be detectable.
The Wrong KPIs
The second reason PPC tests fail in SaaS accounts is that they measure the wrong outcomes. Most PPC testing in B2B SaaS uses platform-native metrics as success criteria: click-through rate, cost-per-click, conversion rate on a form submission, platform-reported CPA. These are available immediately. They are easy to report. They are often the wrong thing to measure. Cost Per Acquisition (CPA) - The Most Critical PPC Metric, also on this blog, takes this further.
The problem is that in B2B SaaS, the outcome that matters commercially is qualified pipeline and closed-won revenue, not form fills. A test that shows a 25% improvement in form submission rate is not necessarily showing a 25% improvement in pipeline. It may be showing a 25% increase in unqualified traffic completing a form. If the test used form fills as the success metric, it will be called a winner and scaled. The lead quality collapse shows up later, in the CRM, weeks after the test has already been implemented.
Three KPI failure modes are particularly common in SaaS PPC testing.
Optimising for the wrong funnel stage. Testing ad copy against CTR when the relevant question is whether the copy attracts the right ICP. CTR and lead quality are largely uncorrelated in B2B SaaS. High CTR often indicates broad appeal, which in practice means more irrelevant clicks. Testing against MQL-to-SQL rate or cost-per-opportunity takes six to eight weeks to measure, but it is the signal that actually matters.
Using platform-reported conversions as the success metric when offline conversions are not imported. If the Google Ads account is optimising against form fills rather than CRM-qualified pipeline, any test using platform conversion data is testing the wrong thing. The form fill rate and the qualified lead rate are often not correlated, particularly in accounts that have not tightened qualification through form design.
Testing elements that affect top-of-funnel metrics while measuring bottom-of-funnel outcomes. A landing page copy test measured against closed-won revenue six months later is not a well-designed test. The causal chain is too long and too noisy. Not because the test is wrong, but because the outcome metric needs to match the timescale and the causal proximity of the variable being tested.
The fix is to match KPIs to the causal layer being tested. Ad copy tests should be measured against CTR and qualified lead rate together, with CTR as a short-term diagnostic and qualified lead rate as the definitive measure. Landing page tests should be measured against form completion rate and MQL rate. Bid strategy tests should be measured against cost-per-opportunity and, where enough data exists, cost-per-SQL.
Poor Stopping Rules
Stopping rules define when a test ends. In most PPC accounts, the implicit stopping rule is one of three things: "when it looks like there’s a winner," "when we’ve run it for a month," or "when the team gets bored of waiting." None of these is a valid stopping rule.
"Peeking" at a test and stopping when it looks like a winner is one of the most common sources of false positives in PPC experimentation. If you check a test every day and stop it the moment one variant is ahead, the probability of a false positive is much higher than the stated confidence level. This is a well-documented problem in frequentist testing: early stopping inflates the type-I error rate. The test appears to produce a winner. The winner does not hold up when implemented.
Arbitrary time-based stopping rules have a different problem: they produce neither correct power nor valid significance. A test that is stopped after four weeks because it is "time to move on" may have reached significance for one metric and not another, or may have been confounded by a weekly seasonality pattern in click behaviour.
Valid stopping rules require deciding, before the test starts, the minimum detectable effect (the smallest improvement that would be worth implementing), the required sample size to detect that effect at the chosen confidence level, and the maximum run time beyond which external factors (seasonality, market shifts) are likely to contaminate the result. Tests that reach the required sample size before the maximum run time can be stopped. Tests that reach the maximum run time before the required sample size should be treated as inconclusive, not called based on whichever variant happened to be ahead at that point.
In B2B SaaS PPC, where reaching required sample sizes in a reasonable timeframe is often not achievable, the honest response is to treat test results as directional rather than conclusive, and to document the confidence level explicitly when acting on them. A result with 75% confidence that one variant is better than another is still useful if it informs a decision that is reversible and the cost of a wrong call is low.

Noisy Attribution and the Pipeline Lag Problem
Even well-designed PPC tests in B2B SaaS face a structural challenge that makes clean causal inference difficult: the pipeline is long, attribution is incomplete, and the outcome that matters (closed-won revenue) arrives weeks or months after the test has finished.
A search click from a Google Ad in week one may become a form submission in week two, an MQL in week three, an SQL in week six, and a closed deal in week fourteen. If a test runs for four weeks and measures form submissions, it is measuring one link in a chain that has twelve more links to go. The test may produce a clear result on form submissions that is irrelevant to commercial outcomes because the form submission rate and the closed-won rate are not correlated for the specific change being tested.
The pipeline lag problem creates a specific failure mode: tests that produce false positives at the form submission level, get implemented based on that result, and degrade pipeline quality over the following quarter. The degradation is not obviously connected to the test decision, because the signal delay is too long for the causal link to be visible without deliberate tracking.
The practical response is to track test cohorts through the pipeline rather than calling tests at the form submission level. Tag all leads generated during each test variant with the variant identifier in the CRM, and then measure MQL rate, SQL rate, and where volume allows, opportunity rate, by variant. This requires four to eight weeks of post-conversion data collection beyond the test run period. It is slower. It produces significantly more reliable learning.
For accounts where this level of cohort tracking is not operationally feasible, the minimum is to monitor the MQL-to-SQL rate of leads generated by each variant in the weeks following the test. A variant that won on form fills but produced a meaningfully lower MQL-to-SQL rate should not be implemented.
Weak Hypotheses
The fifth reason PPC tests fail is the most fundamental: the underlying hypothesis does not contain a mechanism.
A hypothesis like "changing the headline from X to Y will improve conversion rate" is a prediction, not a hypothesis. It does not specify why the change should produce the effect, which means it cannot produce transferable learning even if the result is clear. You tested one headline against another. You learned that one headline performed better on one metric in one campaign during one period. You did not learn anything about what makes headlines work in your category, which buyer psychology you are activating, or what to test next.
A hypothesis with a mechanism sounds like: "Changing the headline from a generic benefit claim to a specific pain statement will improve qualified conversion rate because our ICP is decision-stage buyers who are already convinced of the category and need confirmation of fit, not education about benefits." This hypothesis, if confirmed, teaches something: decision-stage buyers respond to pain framing more than benefit framing. That learning informs the next test, the landing page copy, the ad extensions, and potentially the sales team’s messaging.
The test design question that forces hypotheses to contain mechanisms is: "If this test produces the result we expect, what will we do differently in other parts of the account, and why?" If the answer is "we’ll use the winning variant," the hypothesis is too narrow. If the answer is "we’ll apply pain-framing to all decision-stage copy because our ICP responds to fit confirmation rather than category education," the hypothesis is genuinely informative.
In practice, most SaaS PPC teams run tests because they have been told to "always be testing" rather than because they have specific hypotheses they want to validate. The result is a backlog of tests that produce data but not insight, and an account that is permanently in a state of "testing" without accumulating any learning that compounds.
The fix is to maintain a hypothesis log: a document that records, for each active test, the mechanism being investigated, the predicted outcome, the success metric, the stopping rule, and the expected action if the hypothesis is confirmed or refuted. A hypothesis log also prevents the common problem of forgetting what a test was designed to learn by the time the results come in.
.jpeg)
What Good Experimentation Looks Like in a SaaS PPC Account
A well-designed SaaS PPC experimentation programme has four characteristics.
A prioritised test backlog. Tests are ranked by expected commercial impact multiplied by confidence in the hypothesis, not by ease of implementation. High-impact, well-hypothesised tests get resources first. Small tweaks without clear mechanisms do not enter the queue.
Pre-registered stopping rules. Every test documents its required sample size, minimum detectable effect, confidence threshold, and maximum run time before it starts. Results are evaluated against these pre-registered criteria, not by visual inspection of trending metrics.
Pipeline-level success metrics. Where the conversion volume supports it, tests are measured against MQL rate or cost-per-opportunity rather than form submissions or platform CPA. Where volume does not support pipeline-level measurement, form fill results are treated as directional and tagged for post-conversion cohort tracking.
A learning cadence, not a testing cadence. The rhythm is not "run a new test every month." It is "complete the current test with a valid result, document the learning, update the hypothesis log, and design the next test based on what was learned." A well-designed test that runs for twelve weeks and produces clear learning is more valuable than twelve tests run for a week each that produce noise.
For teams who are also dealing with unexplained performance drops that may or may not be related to their testing activity, the companion piece on PPC performance collapse in B2B SaaS covers the diagnostic process for separating test effects from external account changes. If testing and performance problems are occurring simultaneously, running the collapse checklist before continuing experimentation is the right sequence. For accounts where rising CAC is also a concern, the companion piece on when CAC spikes in Series A+ SaaS PPC accounts covers the failure-mode diagnosis that sits upstream of testing decisions.
Our SaaS PPC experts work through experimentation design regularly with SaaS teams. If your account has been "testing" for months without producing actionable learning, the hypothesis log is usually the first thing to fix.
Frequently Asked Questions
Why do PPC tests fail to produce useful learning in SaaS?
The five most common reasons are: underpowered tests that cannot detect real effects at typical SaaS conversion volumes, wrong KPIs that measure form fills rather than qualified pipeline, poor stopping rules that end tests based on visual inspection rather than pre-registered criteria, noisy attribution that obscures the connection between test variants and commercial outcomes, and hypotheses that specify a predicted outcome without specifying a mechanism. Any one of these produces unreliable results. All five together are the norm in most B2B SaaS PPC accounts.
What is the difference between optimisation and experimentation in PPC?
Optimisation adjusts account variables based on observed performance: pausing keywords, improving quality scores, updating negative lists. It produces incremental improvement within the current strategy without producing transferable learning. Experimentation tests a specific hypothesis about a causal mechanism: if we change X, Y will happen because of Z. The mechanism requirement is what distinguishes a real experiment from an optimisation step dressed up as a test. Real experiments produce learning that informs future decisions. Optimisation produces tactical gains without strategic insight.
How do low-volume SaaS campaigns create false experiment results?
Low conversion volume means wide confidence intervals. At 30 conversions per month split across two variants, week-to-week variation from random sampling can easily exceed the effect size being tested. A variant that appears to be winning by 20% at three weeks may be behind by the same margin at six weeks. Tests stopped early under these conditions frequently produce false positives: the winning variant does not hold up when implemented because the result was noise rather than a real effect.
Which PPC KPIs create misleading test outcomes?
Click-through rate is a misleading primary success metric for ad copy tests because it does not correlate with lead quality in B2B SaaS. Platform-reported conversion rate is misleading when the conversion event is a generic form fill rather than a qualified demo request, because higher form fill rates often indicate broader appeal to lower-intent traffic. Cost-per-click is misleading as a standalone metric because it does not reflect whether the clicks are commercially valuable. In each case, the metric is available quickly and easy to report, but measuring it rather than qualified pipeline produces decisions that degrade lead quality over time.
How do you know when a SaaS PPC test is underpowered?
Calculate the required sample size before the test starts. Decide the minimum detectable effect: the smallest improvement that would be worth implementing. Use a sample size calculator with that effect size, the baseline conversion rate, and the chosen confidence level. If the required sample size exceeds what the account can deliver in a reasonable timeframe, the test is underpowered in its current form. Either increase the traffic to the tested element, target a larger effect size, reduce the confidence threshold to a directional level, or do not run the test.
What stopping rules should PPC teams use for better tests?
Pre-register the required sample size, minimum detectable effect, confidence threshold, and maximum run time before the test starts. Stop the test when it reaches the required sample size or the maximum run time, whichever comes first. Do not peek at results and stop early because one variant appears to be winning: early stopping based on visual inspection inflates false positive rates significantly. If the test reaches maximum run time before the required sample size, treat the result as inconclusive unless the observed effect is large enough to be meaningful even at the lower achieved sample size.
How should lagging pipeline data affect PPC experiment design?
Tag all leads generated during each test variant with the variant identifier in the CRM and measure MQL rate and, where volume allows, SQL rate and opportunity rate by variant in the weeks following the test. A variant that won on form fills but produced a materially lower MQL-to-SQL rate should not be implemented. Where full cohort tracking is not operationally feasible, monitor MQL-to-SQL rate by variant in the post-test period as a minimum quality check. Designing tests to measure outcomes at a funnel stage where the lag is manageable (four to eight weeks rather than six months) is also a valid structural response.
What are the signs of a false experiment in a SaaS account?
A test was called based on visual inspection rather than pre-registered criteria. The result was called after fewer than the required number of conversions. The success metric was a platform-native conversion rather than a pipeline-linked outcome. The winning variant was implemented and performance did not change, or degraded over the following four to six weeks. The test hypothesis did not specify a mechanism, only a predicted direction. Multiple tests ran simultaneously, making it impossible to isolate the effect of any single change. Any of these is a sign that the result is unreliable.
If your account has been testing without producing learning, the problem is almost never the volume of tests. It is the quality of the hypothesis, the validity of the stopping rule, and the relevance of the success metric. Fixing those three things produces more insight from fewer tests than running more tests with the same underlying problems.


